
Cirata and Apache Iceberg
Written by Paul Scott-Murphy, CTO, Cirata
What is Apache Iceberg
Originally a Netflix project, Iceberg was made open source in 2018 and graduated from incubation under Apache Software Foundation governance in 2020. It is now a leading standard for what is called an “open table format”, providing a simple, scalable approach to how data and metadata are structured to support data interoperability for compute platforms. It is designed to operate efficiently when the underlying data storage is based on the functionality of common cloud storage services.
Apache Iceberg defines two key things:
- A table format (not just a file format) for large datasets, and
- Interfaces to that table format for languages and platforms.
The design of Apache Iceberg focuses on managing large datasets held in distributed storage services, and potentially concurrent use by a variety of compute engines.
Why are table formats needed?
Table formats add the definition of data structure on top of files that hold data, so that you can use common tools and techniques to interact with it by using those definitions, like SQL.
Relational databases and data warehouses typically hide the details of how they provide table formats, exposing only a SQL interface. This limits their interoperability, because specific SQL tooling is required to use them. They prevent you mixing more capable tools in the future to access and use the data they hold
Data lakes intentionally separate data storage from data structure, making it possible to employ a range of tools on common data. But without data structure (provided by file formats and table formats) a data lake is just a collection of files or objects.
Table formats are one part of what makes a data lake a data lake, and not just a storage platform. Apache Iceberg is not a storage engine, storage format or execution engine, but an open table format that helps enable data interoperability to give you greater protection from lock-in, and greater choice among competing technologies that use your data.
What distinguishes Apache Iceberg?
The design of Apache Iceberg targets very specific improvements over other table formats, including explicit support for:
- Schema evolution,
- ACID transactions,
- Dynamic and “hidden” partitioning,
- Queries of current or prior table state,
- Separation of metadata from data files, and
- Compatibility with multiple storage services and multiple processing engines.
Its overall design has explicit support for cloud storage services. The defining attributes of them, such as object immutability, structure, etc. are accounted for in the requirements Iceberg has on the storage used for table data. By explicitly targeting how could storage services function, Apache Iceberg can deliver its improvements efficiently at scale.
Why use Apache Iceberg?
Large datasets are cumbersome or costly to use without solutions to problems of:
- Scale,
- Consistency,
- Access,
- Efficiency,
- Evolution,
- Compatibility, and
- Portability.
Apache Iceberg is one good technical approach to address those problems. It does not require specific runtime services to be used in order to function, relying solely on cooperation by design among platforms interacting with it. Multiple engines that work with Apache Iceberg can interact on common data, including making transactional updates to tables, without risk of conflict or data corruption.
Challenges when adopting Apache Iceberg
Organizations that hold data assets in alternate formats will be faced with some challenges when adopting Iceberg.
- Existing data assets may exist in other data formats as a result of accumulating data before Apache Iceberg or its alternatives were available.
- Not all platforms and systems support Apache Iceberg.
While not every platform has direct support for Apache Iceberg, adoption is increasing in commonly-used systems:

How it works
Iceberg tracks individual data files in a table (using a catalog) instead of files in a directory location. This allows Apache Iceberg to optimize interactions with storage to service queries and transactions made against data in tables.
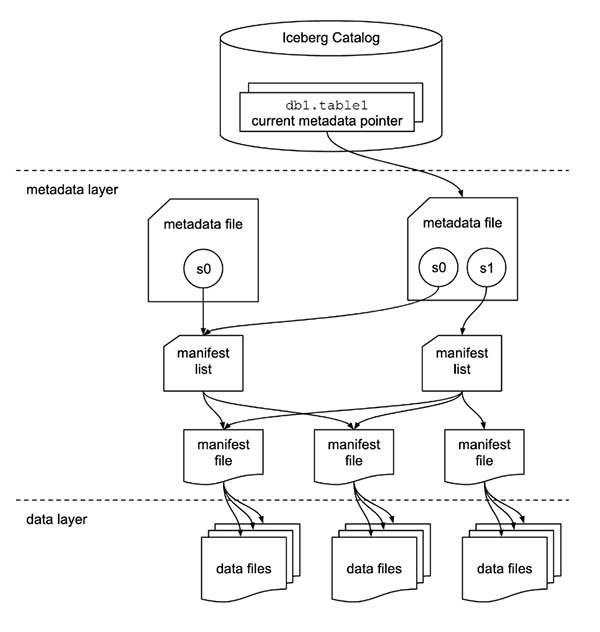
This is a key difference from Hive table formats, which use the directory location of files to define the data content of a table, which imposes a need for directory scans to read content for a table, a potentially expensive operation at scale on cloud storage.
Other features of Iceberg benefit from this simple approach:
- Transactions,
- Snapshots, tagging, branches,
- Schema evolution,
- Speed of operation planning.
Apache Iceberg uses optimistic concurrency for transactions.
- Transactions are based on the atomic swap of one metadata file for another in the catalog.
- Writers detect transaction validity at commit time, and must re-attempt a commit if the snapshot on which it was based is no longer valid.
- Snapshots created for a commit are assigned a sequence number that is used in the manifest list (the metadata for manifest files).
Iceberg requires that storage systems provide support for three operations:
- In-place write - Files are not moved or altered in storage once they are written
- Seekable reads - Data file formats require seek support
- Deletes - Tables delete files that are no longer used
The Iceberg Catalog
Using Iceberg also requires a catalog that is able to hold the information needed to define an Iceberg table, and provides a selection of catalog types that are commonly used. Tasks like creating, dropping, and renaming tables are the responsibility of a catalog. Apache Iceberg supports multiple catalog types.
An Iceberg client configures its use of a specific catalog before doing anything else with Iceberg. This is typically just a set of processing engine properties. E.g. for Spark, catalogs are configured using properties under spark.sql.catalog.(catalog_name):
- A URI string pointing to the catalog,
- The root path for the warehouse,
- The catalog type, plus other optional properties.
Apache Iceberg is flexible
Apache Iceberg is file format agnostic, capable of having multiple types of file format used for the actual table data: Parquet, Avro, ORC, etc. It also provides long-term pluggability for new file formats, allowing the specification to adapt to advances and improvements in data formats.
It is also agnostic to the processing engines that use it. Iceberg defines rules for how to operate against data in transactions, and does not require any other coordination performed by a system external to clients, just an an-place swap in the catalog of the pointer to the current metadata file.
Unlike Apache Hive, there is no additional runtime component needed to use Iceberg. An existing Hive metastore could be used as the catalog, or you could choose an alternative, including just the file storage system (if Hadoop-compatible) in which data are held.
The easiest way to start is by adding Iceberg support to a Spark cluster, or accessing a prepared environment like IBM watsonx.data.
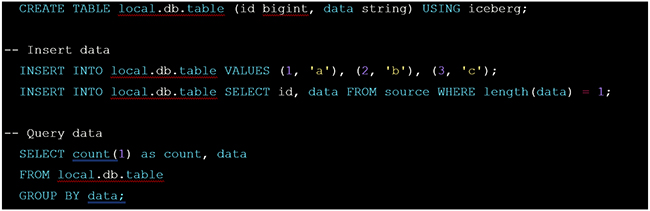
Examples of using Iceberg
Here are some examples of how to interact with Iceberg tables using Spark SQL:
Interface to Apache Iceberg
Beyond its specification, the Apache Iceberg project provides
- Libraries for Java and Python,
- Integration with specific compute engines:
- Spark (the most mature)
- Flink
- Hive
- Trino
- Clickhouse
- Presto
- Dremio
- StarRocks
- Amazon Athena
- Amazon EMR
- Impala
- Doris
- Integrations with AWS services
- Iceberg Catalog options
- DELL ECS
- Relational database via JDBC
- Nessie
- Hive Metastore
- REST API
- Hadoop file system
- Support for converting existing tables in other formats to Iceberg.
Why Apache Iceberg is important
Apache Iceberg is an important advancement for organizations adopting or operating data lakes. The key aspects to understand in assessing its potential for your organization are:
- Iceberg is strategically differentiated, not just technically
- It is open and interoperable by design, promoting choice and competition among compute engines, storage and platform vendors.
- It has growing adoption among significant platforms
- BigQuery, Databricks, Redshift, Snowflake, SingleStore, IBM watsonx, etc. New support from other platforms is being added every day.
- It provides transactional access to structured data at scale
- It only requires a storage system to honor simple storage behaviors, and enables you to take better advantage of your choices of compute, analytics and AI engines, increasing their value to your organization.
Read more about how Cirata supports Apache Iceberg with Cirata Data Migrator, and reach out to us if you need more support with your data strategies.
- It only requires a storage system to honor simple storage behaviors, and enables you to take better advantage of your choices of compute, analytics and AI engines, increasing their value to your organization.
Resources and Alternatives
Resources
- Official Documentation: https://iceberg.apache.org/
- Table Specification: https://iceberg.apache.org/spec/
- GitHub Repository: https://github.com/apache/iceberg
Alternatives:
- Delta Lake: https://delta.io/
- Apache Hudi: https://hudi.apache.org/


