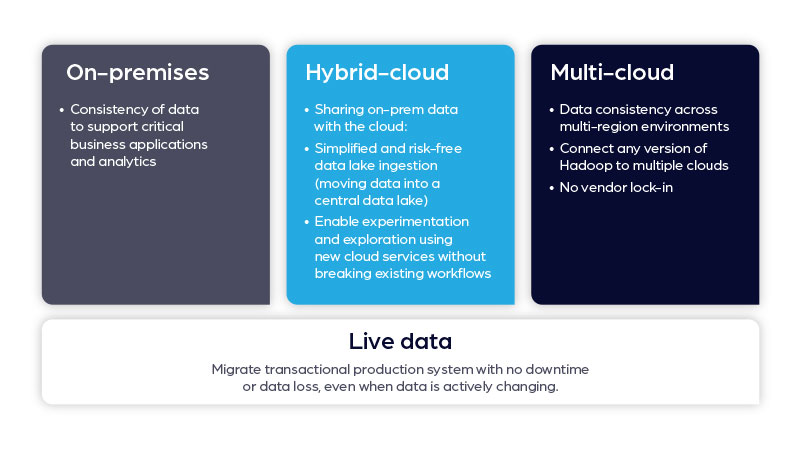
Navigating the complexities of migrating Cloudera/Hadoop data to Databricks can be daunting. Cirata streamlines this process, addressing multiple challenges with precision and expertise, ensuring a seamless transition for your data workloads.
Data migrations can block or slow Databricks adoption with the following issues:
- Large data volumes
- High change rate
- In-house migrations solutions take too long
Automation simplifies data migration projects with the following benefits:
- Migrate data straight Into DeltaLake format
- Time to benefit reduced
- Begin consuming Databrick Units (DBU’s) earlier in the migration project
- Realize new revenue streams earlier